
모든 것을 재귀적으로 구현한 댓글 기능에서 이어집니다
lexical order, 혹은 lexicographic order라고도 불리는 사전적 정렬은 문자열을 유니코드 기준으로 오름차순 정렬하는 방식을 의미한다. 다른 언어에서는 어떨지 모르겠지만, 적어도 자바스크립트에서는 배열의 sort 메서드에 콜백 함수를 전달하지 않으면 기본적으로 이 사전적 정렬이 적용된다.
사전적 정렬의 특징은 직관적이다. 예를 들어 acquaintance는 언제나 b보다 앞서며, "1"로 시작하는 어떤 문자열 역시 "2"보다 항상 먼저 온다. 이 단순한 특성을 활용하면, 무한한 깊이의 대댓글 구조를 매우 간단한 방식으로 표현할 수 있다.
다만 미리 밝혀두자면, 사전적 정렬을 활용하는 방식이 모든 문제를 해결해 주는 만능 해법은 아니다. 이전에 재귀 구조로 댓글을 구현했을 때 그 구조 자체가 문제를 내포하고 있었던 것처럼, 사전적 정렬을 활용하는 방식 역시 필연적으로 구조적인 한계를 가진다. 이 한계가 무엇인지는 뒤에서 다시 다루도록 하겠다.
핵심 아이디어
사전적 정렬에 따르면 "1"로 시작하는 문자열은 반드시 "2"보다 앞선다. 이 성질을 활용하면 댓글의 깊이(depth) 를 문자열로 표현할 수 있다. 여기서 말하는 댓글의 깊이란, 게시글에 직접 달린 댓글을 깊이 0으로 두고, 그 댓글에 달린 대댓글을 깊이 1, 그 아래를 깊이 2로 두는 구조를 의미한다.
나는 이 깊이를 문자열 안에서 표현하기 위해 마침표(.) 를 사용했다. 예를 들어 댓글의 id가 1이나 2라면 깊이는 0이고, 1.1.1이나 2.1.3이라면 깊이는 2가 된다. 즉, 마침표의 개수 = 댓글의 깊이인 셈이다.
이 방식의 장점은 댓글 간의 관계가 문자열 자체에 명확하게 드러난다는 점이다. 3.3.2는 언제나 3.3의 대댓글이고, 1.1.1.1은 언제나 1.1.1의 대댓글이다.
게시글
ㄴ 댓글 // 1
ㄴㄴ 대댓글 // 1.1
ㄴㄴㄴ 대대댓글 // 1.1.1
ㄴㄴㄴ 대대댓글 // 1.1.2
ㄴㄴ 대댓글 // 1.2
ㄴ 댓글 // 2
ㄴㄴ 대댓글 // 2.1이 마침표 깊이 표기법은 추가적인 이점도 제공한다. 별도의 관계 테이블 없이도 부모–자식 관계를 추론할 수 있다는 점이다. 3.3.2의 부모를 알고 싶다면 3.3을 조회하면 되고, 3.3의 모든 대댓글을 찾고 싶다면 3.3.을 포함하는 id를 조회하면 된다.
모델 설계
이전의 재귀 기반 모델과 달리, 이 방식은 댓글 테이블이 자기 자신을 참조할 필요가 없다. 심지어 초기 아이디어 단계에서는 게시물 테이블과의 직접적인 연결조차 필요 없다고 생각했다. 이유는 간단하다. 댓글의 id를 게시물의 id에서 파생시키면, 그 자체로 유니크함을 보장할 수 있기 때문이다. 게시물의 id가 UUID라면, 그 뒤에 마침표 깊이 표기법을 이어 붙이더라도 충돌이 발생할 가능성은 없다.
⚠️ 경고
위의 설명은 Prisma의 contains 필터를 사용하는 경우를 전제로 한 초기 아이디어다. 하지만 contains는 인덱스를 타지 못할 가능성이 높고, 데이터가 많아질수록 전체 테이블 스캔으로 이어질 수 있다. 따라서 실제 구현에서는 게시물 테이블과의 관계를 명시적으로 연결하는 것이 여전히 중요하며, 작성자 확인을 위해 유저 테이블과의 관계 역시 필수적이다.
이후 구현은 댓글–게시물 간 관계를 명시적으로 연결하는 방향으로 수정되었으며, 아래 모델은 그 결과물이다.
model Comment {
id String @id @unique @db.Text
comment String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
userId String
user User @relation(fields: [userId], references: [id])
reportId String
report Report @relation(fields: [reportId], references: [id])
}쿼리 조회
재귀적으로 댓글을 조회하면 결과는 필연적으로 중첩 배열이 된다. 이 구조에서는 페이지네이션을 구현하는 것이 사실상 불가능에 가깝다.
반면 마침표 깊이 표기법을 사용하면, 조회 결과는 언제나 1차원 배열이다. 댓글의 깊이는 오직 문자열에 포함된 마침표의 개수로만 결정된다. 이 덕분에 오프셋 기반이든 커서 기반이든 페이지네이션을 매우 단순하게 구현할 수 있다.
getComments(reportId: string, offset: number, limit: number) {
return this.prisma.comments.findMany({
where: { reportId },
orderBy: { id: 'asc' },
skip: offset,
take: limit,
include: {
user: {
select: {
id: true,
nickname: true,
profileImage: true,
},
},
},
});
}실제로 조회 결과를 확인해보면, id의 사전적 정렬에 따라 댓글과 대댓글이 의도한 순서대로 나열되는 것을 확인할 수 있다.
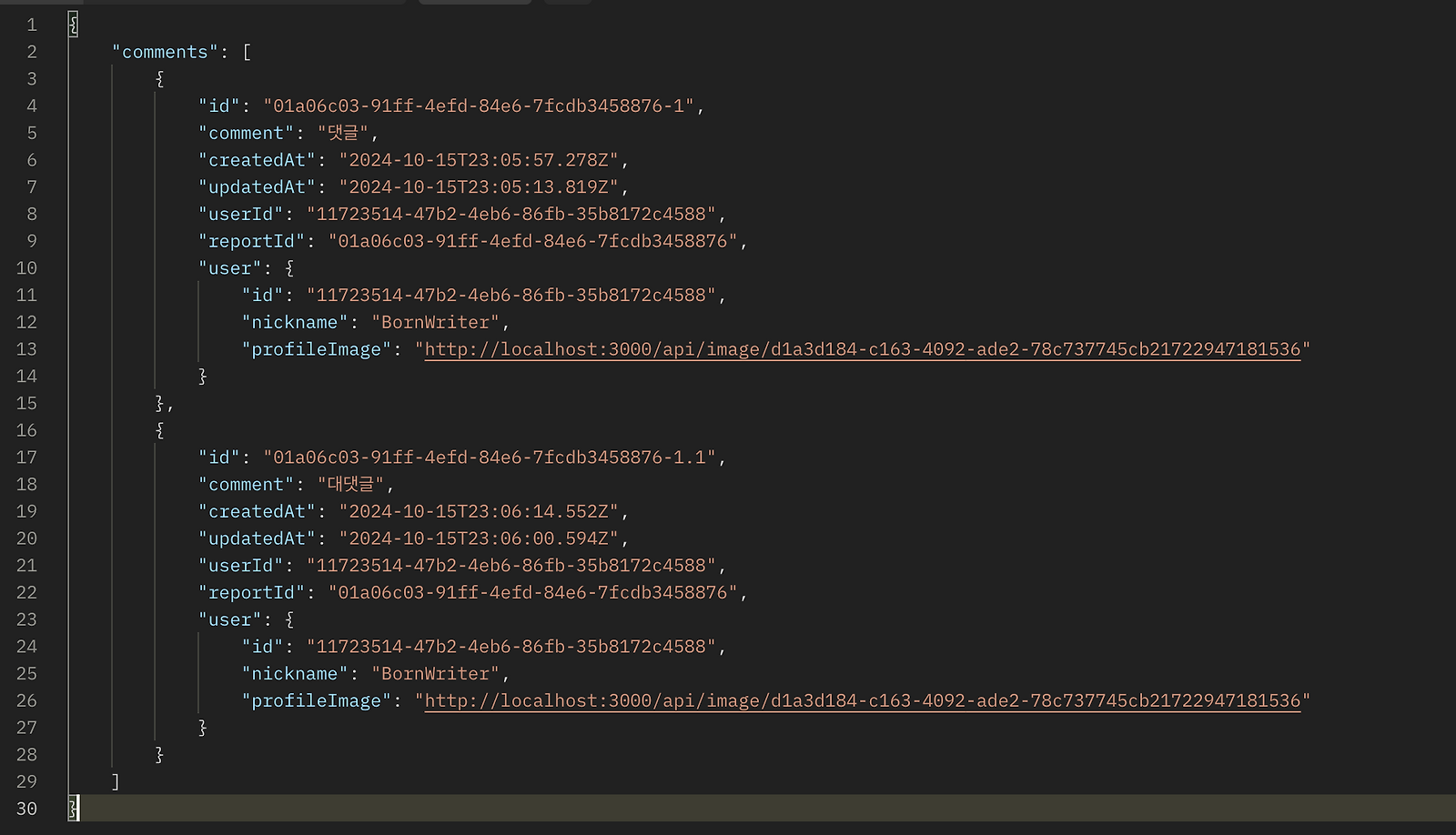
사전적 정렬의 구조적 문제
여기까지만 보면 사전적 정렬은 모든 문제를 해결해 주는 만능 도구처럼 보인다. 하지만 실제로는 그렇지 않다.
문제는 숫자가 문자열로 취급된다는 점이다. 예를 들어 1번 댓글에 달린 열 번째 대댓글은 1.10이 된다. 하지만 사전적 정렬에 따르면 "1.10"은 "1.2"보다 앞선다. 즉, 열 번째 댓글이 두 번째 댓글보다 먼저 정렬되는 것이다.
이를 해결하기 위해 흔히 사용하는 방법이 고정 길이 패딩이다. 숫자를 그대로 사용하지 않고, 00001, 00002처럼 고정된 길이의 문자열로 변환하는 방식이다.
게시글
ㄴ 댓글 // 00000
ㄴㄴ 대댓글 // 00000.00000
ㄴㄴㄴ 대대댓글 // 00000.00000.00000
ㄴㄴㄴ 대대댓글 // 00000.00000.00001
ㄴㄴ 대댓글 // 00000.00001
ㄴ 댓글 // 00001
ㄴㄴ 대댓글 // 00001.00001이 방식 역시 구조적인 한계를 가진다. 예를 들어 패딩 길이가 5라면, 하나의 댓글에는 최대 99999개의 대댓글만 달 수 있다. 하지만 현실적으로 이 정도 제한은 대부분의 서비스에서 충분히 크다. 유튜브 같은 초대형 플랫폼조차 단일 영상의 0깊이 댓글이 1억 개를 넘는 경우는 드물다. 따라서 충분한 패딩 길이만 확보한다면, 고정 길이 패딩은 현실적인 해법이다.
댓글 작성
재귀 구조에서는 부모 댓글의 id만 알고 있으면 자식 댓글을 쉽게 생성할 수 있었다. 하지만 사전적 정렬 방식에서는 부모 id만으로 다음 자식의 id를 바로 알 수 없다.
다행히 부모 댓글의 모든 자식을 조회할 필요는 없다. 오름차순이 아니라 내림차순으로 하나만 조회하면 된다.
async getLastComment(reportId: string, path: string) {
const result = await this.prisma.comments.findMany({
where: {
AND: [
{ reportId },
{
id: {
contains:
path !== 'root'
? `${reportId}-${path}.`
: `${reportId}-`,
},
},
],
},
orderBy: { id: 'desc' },
take: 1,
select: { id: true },
});
return result[0];
}자식 댓글이 없다면 부모 id 뒤에 패딩된 0을 붙이면 되고, 이미 존재한다면 마지막 숫자에 1을 더해주면 된다. 말로 설명하면 복잡해 보이지만, 코드로 보면 생각보다 단순하다.
const getNextId = (path: string, comment?: { id: string }) => {
const PADDING_LENGTH = 5;
if (path === 'root') {
if (comment) {
const part = comment.id.split('-').at(-1).split('.').at(0);
return (Number(part) + 1).toString().padStart(PADDING_LENGTH, '0');
}
return ''.padStart(PADDING_LENGTH, '0');
}
if (comment) {
const part = comment.id
.split('-')
.at(-1)
.replace(`${path}.`, '')
.split('.')
.at(0);
return `${path}.${(Number(part) + 1)
.toString()
.padStart(PADDING_LENGTH, '0')}`;
}
return `${path}.${''.padStart(PADDING_LENGTH, '0')}`;
};더 읽어보기
2025.05.21
14. Redis를 사용한 세션 관리 및 캐싱
새로운 프로젝트를 준비하면서 인증 방식부터 다시 고민하게 되었다. 이전 프로젝트에서는 JWT를 사용해 유저 인증과 상태 관리를 처리했지만, 이번에는 Redis를 활용한 세션 방식으로 전환하기로 결정했다. 이 방식은 유저 상태를 서버에서 직접 관리할 수 있어 보안 측면에서도 유리하고, 필…
2025.01.30
비즈니스 로직은 어디에 있어야 할까
Nest.js에서 컨트롤러와 각각의 프로바이더는 분명한 책임을 갖는다. 하지만 막상 서버를 개발하다 보면, 이 책임들을 깊이 고민하지 않은 채 코드를 작성하게 되고, 그 결과 클래스들이 서로의 영역을 침범하는 상황이 반복된다. 나 역시 컨트롤러에 비즈니스 로직이 섞이거나, 서비스가 지나…
2024.12.07
라이브러리를 죽여버릴 수야 없겠지만
상황 Nest.js 서버에서 jest를 사용한 테스트 코드를 작성하고 있었다. 평소에는 아래와 같이 ConfigService를 모의하여 configService.get으로 환경 변수를 처리했다. 그런데 이런 방식이 마음에 들지 않았다. 가장 큰 이유는 필요한 문자열이 하드코딩 되어있어…
2024.12.07
13. Jest 테스트 구성
이 포스트를 시작하기에 앞서 한 가지 분명히 밝혀두고 싶은 점이 있다. 나는 컨트롤러(혹은 GraphQL 기준으로는 리졸버) 와 레포지토리 클래스에 대한 테스트를 거의 작성하지 않는다. 이유는 단순하다. 애플리케이션에서 가장 많은 비즈니스 규칙이 응집되어 있는 곳은 서비스 계층이며, 테…
2026.06.01
React Server Components를 위한 컴포넌트 아키텍처
이 포스트는 Vercel의 Next.js 팀 소속 개발자 Aurora Scharff가 자신의 블로그에 올린 Component Architecture for React Server Components 게시글을 번역한 것이다. 번역하는 과정에서 다소 의역이 있을 수 있으며, 일부 번역에는…
2026.05.26
차트는 멈췄는데 윈도우가 움직인다
상황 어느날 서비스를 살펴보시던 팀장님께서 이런 말씀을 slack에 남기셨다. 진호님, 예측 차트에서 zoom을 계속하면 어느 순간 라인 차트가 아니라 단일 스캐터 차트처럼 보이는 데, 이거 수정하면 좋을 거 같아요. 어느정도 zoom을 하면 그 이후로는 zoom이 안 되도록 할 수 없…
2026.05.21
피자가게로 이해하는 디자인 패턴
에이든 피자는 처음부터 복잡한 시스템을 만들 생각이 없었다. 처음에는 메뉴 몇 개만 만들면 됐다. 그런데 손님은 커스텀 주문을 넣기 시작했고, 주방은 상태를 나눠야 했고, 결제와 배달앱과 알림이 하나씩 붙었다. 코드도 가게를 닮는다. 장사가 잘될수록 이상하게 더 쉽게 망가진다. 디자인…
2026.05.21
7. Decorator — 토핑 추가할 때마다 클래스를 새로 만들 수 없다
에이든 피자에서 주문서를 객체로 만들자 취소와 재주문은 한결 편해졌다. 그런데 주문이 편해지자 손님들도 한결 편해졌다. 편해진 손님은 더 많은 요구를 한다. "치즈 추가요", "올리브도 추가요", "소스 많이요", "조금 더 바삭하게 구워주세요" 같은 요청이 주문대 위로 쌓이기 시작했다…
댓글
댓글을 불러오는 중...